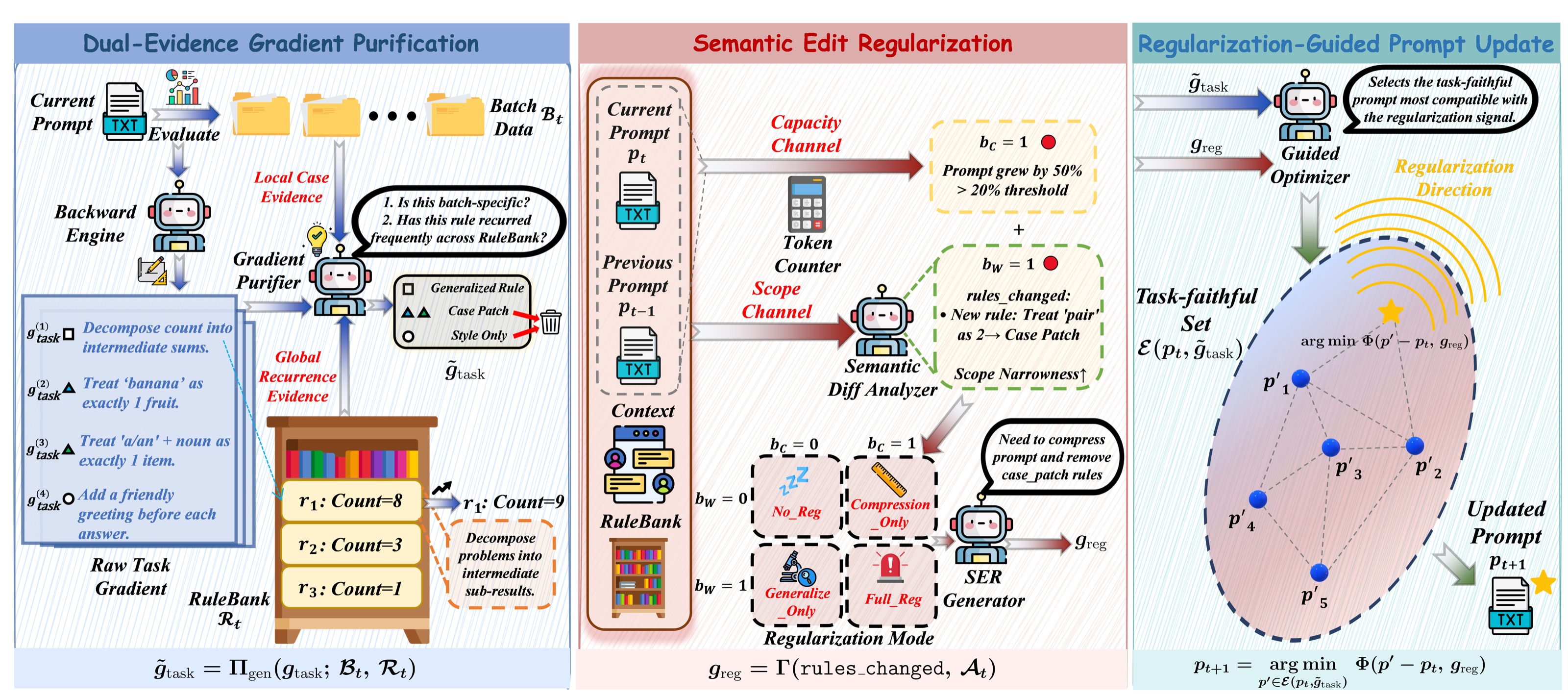
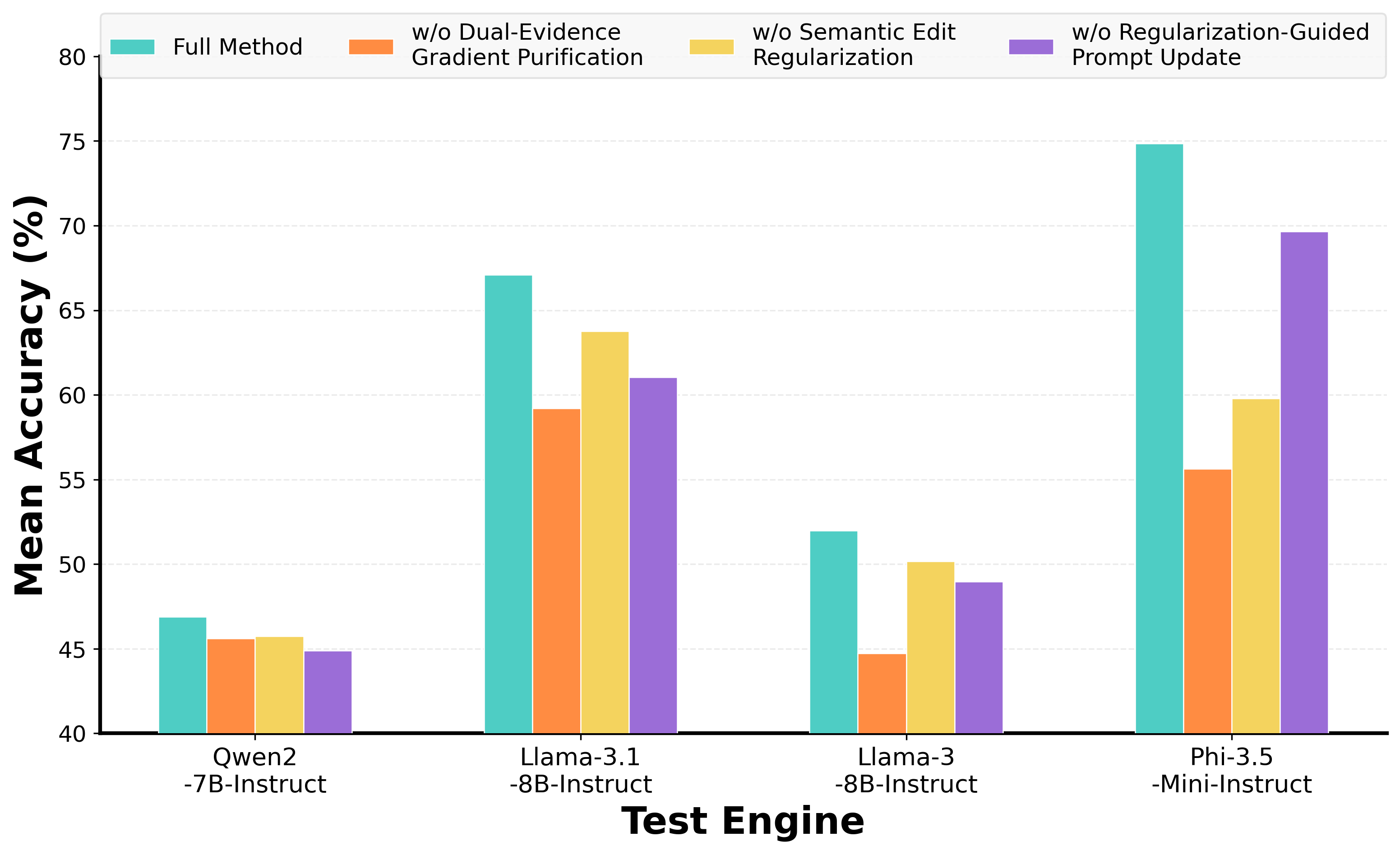
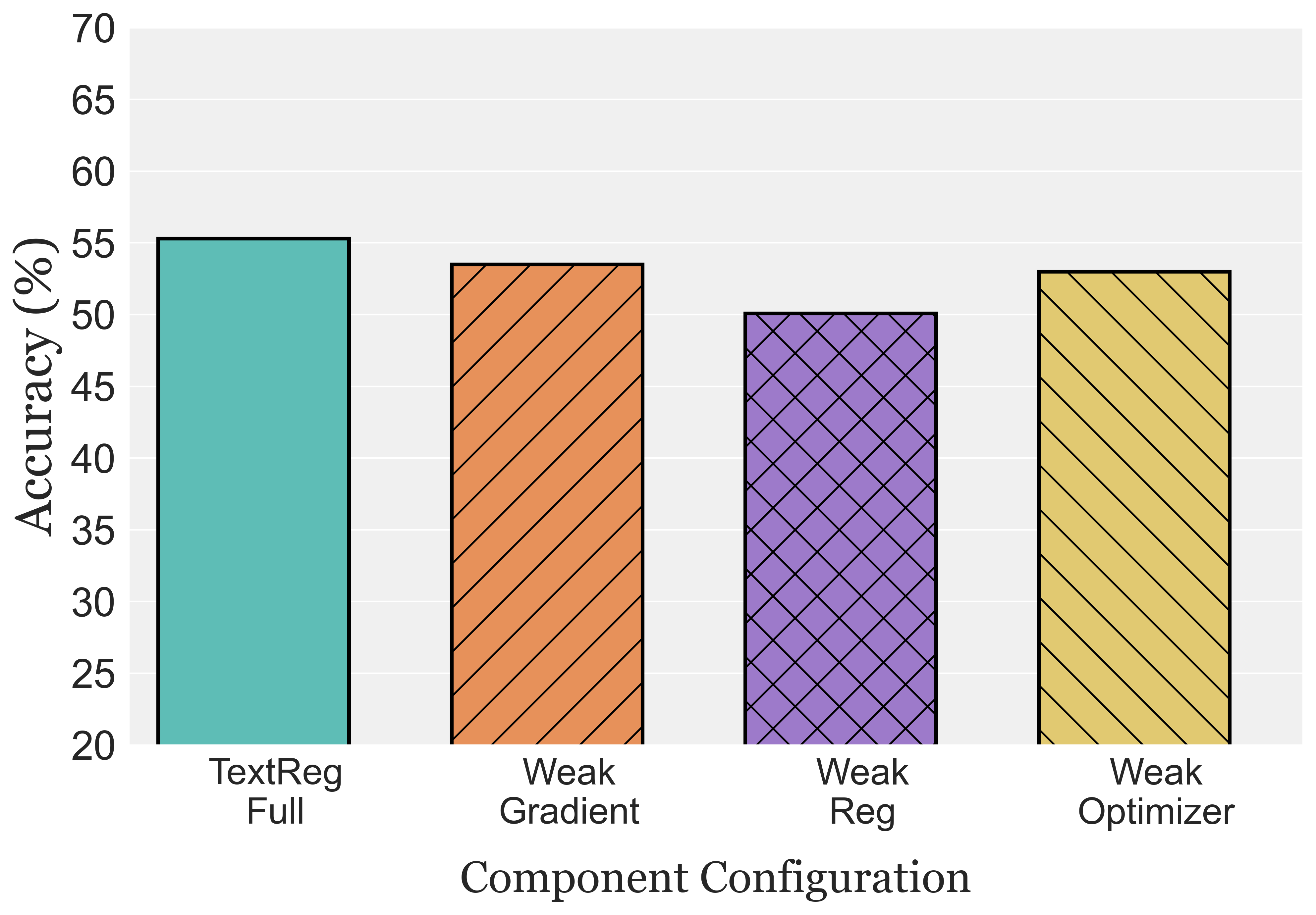
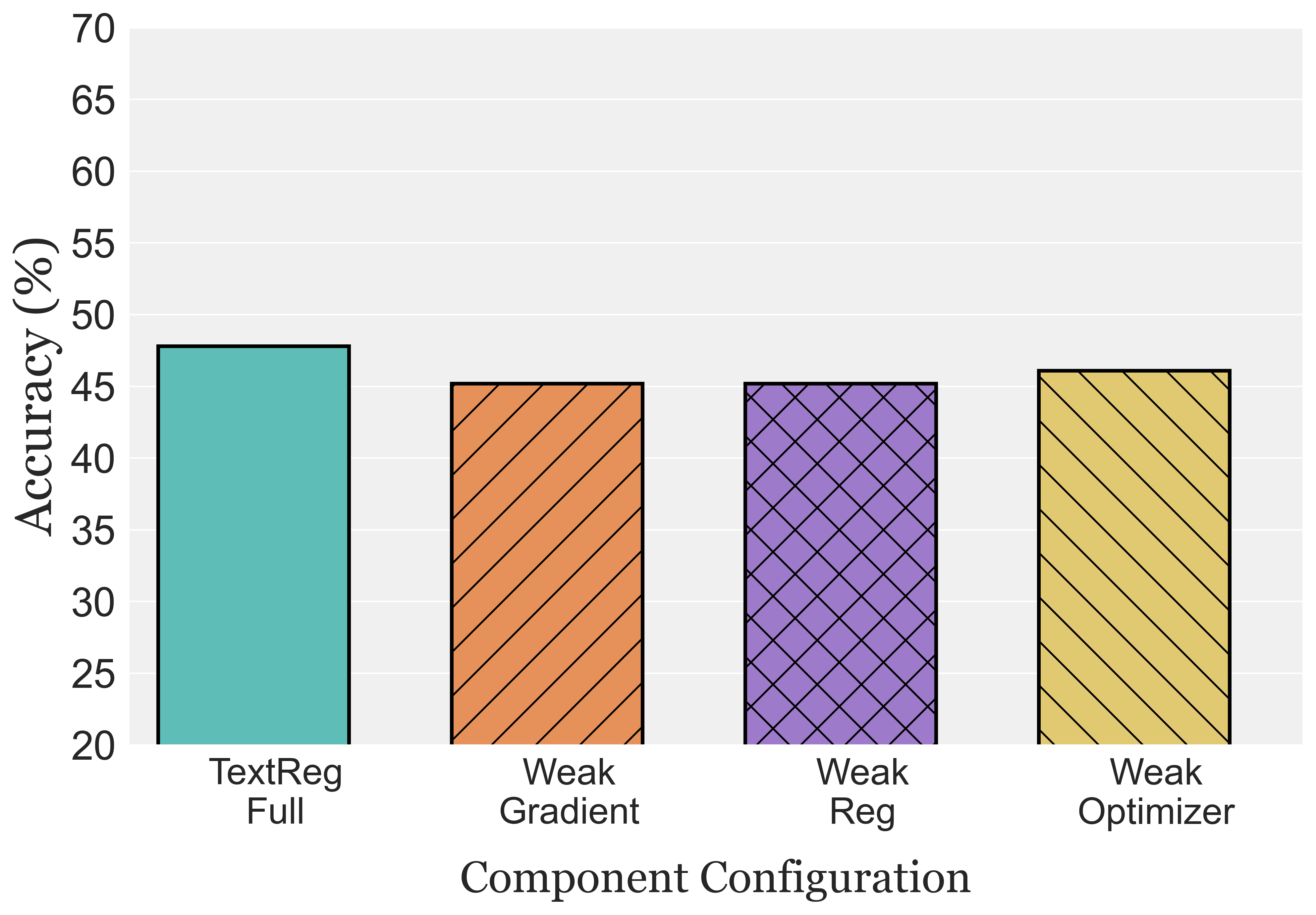
Prompts grow long and narrow — and then fail out of distribution.
As feedback-driven prompt optimizers iterate, they tend to append rules, exceptions, and stylistic constraints that fit a handful of training examples. The result: prompts that swell in length while their rules drift toward narrow, sample-specific patches. We call this failure mode prompt distributional overfitting and frame it as representational inefficiency — the coupled growth of capacity cost and scope narrowness.
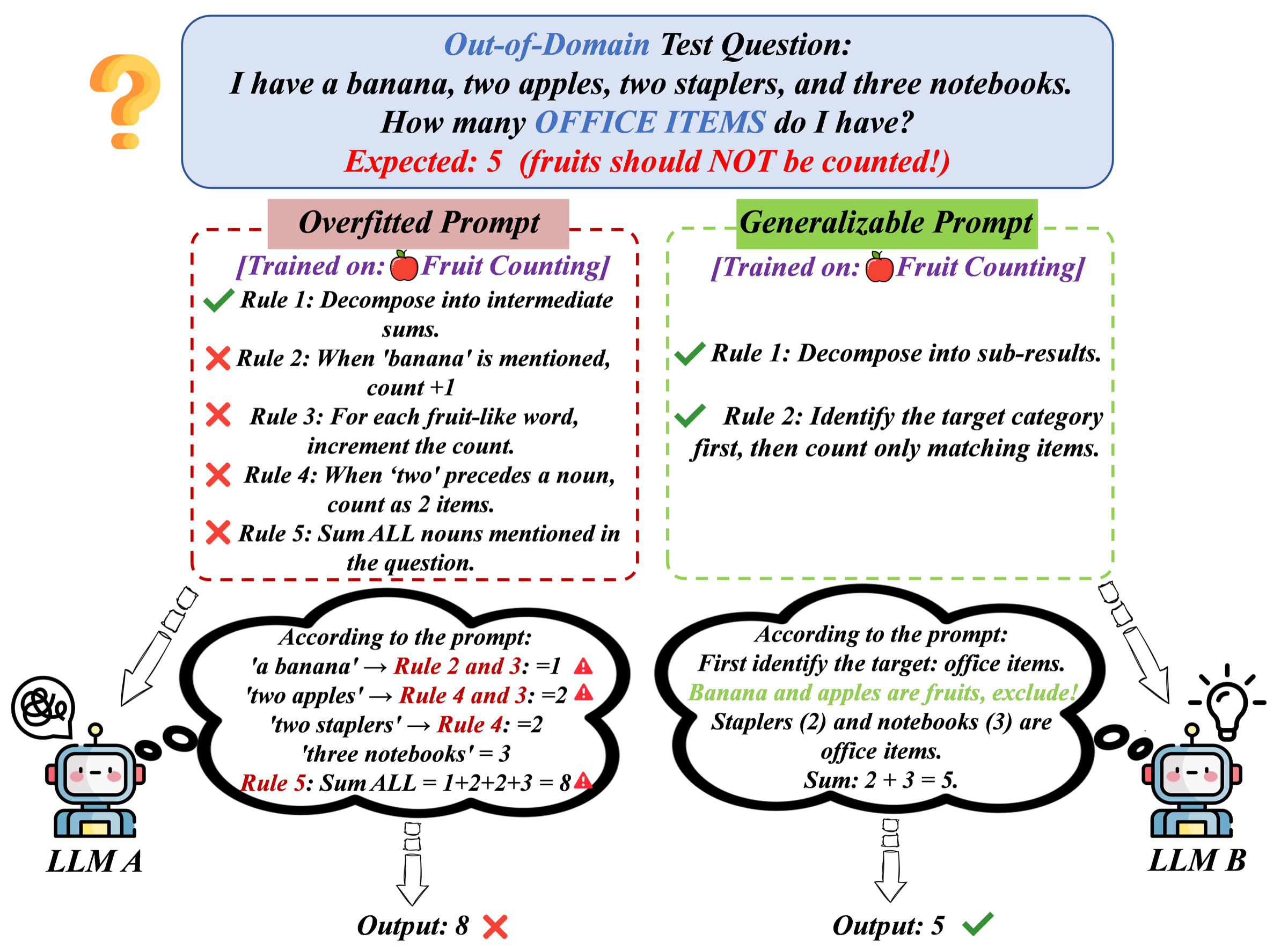
Problem illustration. Conventional methods produce long prompts saturated with narrow rules that degrade on OOD inputs (left). TextReg yields compact prompts of broadly applicable rules for stronger OOD generalization (right).
Longer prompts consume context budget and make it harder for the model to reliably locate and leverage relevant instructions.
Accumulated rules apply only to a small subset of inputs, functioning as ad-hoc patches rather than reusable task principles.
𝓘(p) = C(p) · W(p) — their coupled growth wastes prompt capacity and drives OOD failure.